吴恩达深度学习课程第二课
[TOC]
什么是方差和偏差?
方差:如果一个模型的方差较高,意味着模型对于训练数据的小变化非常敏感,可能会导致过拟合(Overfitting)的问题,
偏差:偏差衡量了模型的预测值与实际观测值之间的差异或偏移。具体来说,它表示了模型在训练数据上的平均预测误差。如果一个模型的偏差较高,意味着模型在训练数据上不能很好地拟合,可能会导致欠拟合(Underfitting)的问题
欠拟合就是没把大头当回事,过拟合就是将偶然太当真
当涉及到模型的方差和偏差时,可以使用具体的例子来更好地理解这两个概念:
假设你正在开发一个简单的线性回归模型,用于预测房屋价格。你有一个包含房屋价格和各种特征(例如房屋大小、卧室数量、地理位置等)的数据集。以下是对方差和偏差的具体解释:
- 方差:
- 假设你多次随机划分你的数据集为训练集和测试集,然后训练相同的线性回归模型。如果不同训练集上训练的模型对于相同测试集产生的预测结果差异很大,那么模型的方差较高。这可能表示模型对于训练数据的小变化非常敏感。
- 例如,如果在一次模型训练中,模型预测某个房屋价值为$300,000,而在另一次训练中,相同模型对同一房屋的预测结果是$350,000,那么模型的方差较高。
- 偏差:
- 偏差表示模型的预测值与实际观测值之间的平均差异。如果你的线性回归模型对于训练数据集中的大多数房屋都产生了相对较大的预测误差,那么模型的偏差较高。
- 例如,如果线性回归模型对于所有房屋都低估了实际价格,那么它具有较高的偏差。
在实际机器学习应用中,你希望找到一个平衡点,使模型的方差和偏差都保持在适度水平。这可能需要尝试不同的模型复杂度(例如,多项式回归的不同阶数)、数据集大小、正则化技术等,以确保你的模型能够在训练数据和未见过的数据上都表现良好。这个平衡点有助于防止过拟合和欠拟合,从而获得更好的泛化性能。
如何解决?
偏差高:欠拟合了,增加模型复杂度,先提升训练集上的性能,
方差高:扩充数据集、正则化、或者其他模型结构来解决高方差
正则化:
意思就是在成本函数J找到最小值 但是i成本函数更改了一点 加上了omit $L_{2}$ regulazation 函数
此方法称为 L 2 正则化。因为这里用了欧几里德法线,被称为向量参数w 的 L 2 范数。
为什么正则化可以减少过度拟合?
- L1正则化通常用于特征选择和稀疏建模,因为它倾向于将某些参数压缩到零,从而实现了特征选择的效果。
- L2正则化有助于改善模型的稳定性和泛化能力,但不会将参数压缩到零,因此它不太适用于特征选择,而更适合用于降低模型的复杂性。
复杂性惩罚:正则化向模型的损失函数添加一个正则化项,该项惩罚复杂模型。正则化项的大小由正则化强度参数(通常表示为λ)控制。
特征选择:在L1正则化等一些技术中,正则化会导致某些模型参数变为零,从而实现了特征选择。这意味着模型忽略了一些不重要的特征,只保留了与任务相关的特征。
降低参数之间的相关性:L2正则化等技术可以减小参数的幅度,从而降低了参数之间的相关性。相关性较高的参数可能导致模型对输入数据中的小变化过于敏感。
泛化性能:正则化的主要目标是改善模型在未见过的数据上的性能,即提高模型的泛化性能。通过控制模型的复杂性,正则化可以帮助模型更好地适应新数据,而不仅仅是训练数据。
为什么L1会导致某些w参数越来越小 ?

求出$dw^{[l]}$后进行$w^{[l]}$更新时候 会导致

$w^{[l]}$时刻变小
Dropout正则化
意思就是i随机失活神经网络层的某层的各个节点 ,以便解决过度拟合的问题。
如何实施?
常用的
即inverted dropout(反向随机失活),出于完整性考虑,我们用一个三层( l = 3 )网络来举例说明。编码中会有很多涉及到3的地方。我只举例说明如何在某一层中实施dropout。
1.首先要定义向量 d , $d^{[3]}$ 表示一个三层的dropout向量:
1 | d3=np.random.rand(a3.shape[0],a3.shape[1]) |
然后看它是否小于某数,我们称之为keep-prob,keep-prob是一个具体数字,上个示例中它是0.5,而本例中它是0.8,它表示保留某个隐藏单元的概率,此处keep-prob等于0.8,它意味着消除任意一个隐藏单元的概率是0.2,它的作用就是生成随机矩阵,如果对 $ a^{[3]}$进行因子分解,效果也是一样的。$d^{[3]}$ 是一个矩阵,每个样本和每个隐藏单元,其中$ d^{[3]}$
2接下来就是将获取的激活函数与得到的d3矩阵乘一下 去掉某些节点
接下来要做的就是从第三层中获取激活函数,这里我们叫它 $ a^{[3]} $ , $ a^{[3]} $ 含有要计算的激活函数, $ a^{[3]} $
等于上面的 $ a^{[3]} $ 乘以 $ d^{[3]} $ ,a3 =np.multiply(a3,d3),这里是元素相乘,也可写为 $ a^{[3]}*=d^{[3]} $
,它的作用就是让 $ d^{[3]} $ 中所有等于0的元素(输出),而各个元素等于0的概率只有20%,乘法运算最终把 $ d^{[3]} $
中相应元素输出,即让 $ d^{[3]} $ 中0元素与 $ a^{[3]} $ 中相对元素归零。

如果用python实现该算法的话,$ d^{[3]}$ 则是一个布尔型数组,值为true和false,而不是1和0,乘法运算依然有效,python会把true和false翻译为1和0,
3最后我们向外扩展$ a^{[3]}$,用它初一0.8,或者说是除以keep-prob的参数
为什么除以这个参数 意思就是最后我们得到$z^{[4]}$的时候 由于$z^4 = w^{[4]} * a^{[3]} + b^{[4]}$所以 $a^{[3]}$中有些元素被归零影响得到$z^{[4]}$的值
所以要除以keep-prob参数 弥补那损失的值
总结:Dropout方法参数尽量处在0.9左右 因为大量的失活可能会导致一些
其他正则化方法:
一.数据扩增
就是将一组数据变形进而加入训练集,从而增加训练集。
二.early stopping
就是训练代价函数J 的时候优化到一定的值后就停止优化。
early stopping代表提早停止训练神经网络,但是你并不知道什么时候停止。
归一化输入
第一步是零均值化。
第二步是归一化方差
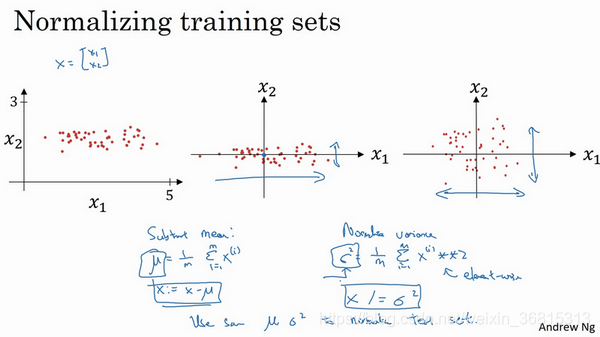
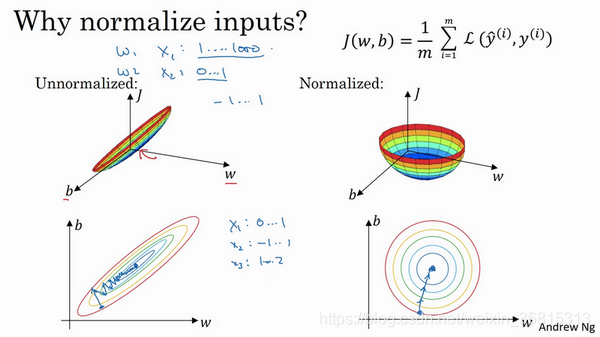
意思就是要让数据在一个范围内,不然处理的时候可能会有偏差。不然做梯度下降的时候可能会很慢。
梯度消失和梯度爆炸
意思就是在进行梯度计算的时候梯度优化w的时候可能会进行指数增长或者指数下降,层数躲起来的时候可能会对神经网络
计算产生影响。
下面是梯度爆炸和消失 就是 1.5的n次方和0.5的n次方一个接近无穷一个接近0 这就会导致梯度爆炸和消失

神经网络的权重初始化
意思就是初始化W根据不同的激活函数得到不同的权重初始化值
- 权重$W^{[l]}$应该随机初始化以打破对称性。
- 将偏差$b^{[l]}$初始化为零是可以的。只要随机初始化了$W^{[l]}$,对称性仍然会破坏。
梯度检验1.13 梯度检验-深度学习第二课《改善深层神经网络》-Stanford吴恩达教授_Zhao-Jichao的博客-CSDN博客
- 梯度检验可验证反向传播的梯度与梯度的数值近似值之间的接近度(使用正向传播进行计算)。
- 梯度检验很慢,因此我们不会在每次训练中都运行它。通常,你仅需确保其代码正确即可运行它,然后将其关闭并将backprop用于实际的学习过程。
[TOC]
mini-batch 梯度下降法
意思就是向量化能够让你有效地对所有 m mm 个样本进行计算,允许你处理整个训练集,而无需某个明确的公式。所以我们要把训练样本放大巨大的矩阵 X XX 当中去,但是向量如果变得多了比如500 万个或者是更大的数,在对整个训练集执行梯度下降法时候,一个个的去正向传播会很慢。
所以如下图引入了一个子集 就是每个子集上面存放1000个X向量 ,在些子集被称为mini-batch 可以分成5000个 这个时候就得5000个mini-batch

同理对Y也进行相同的处理,也要相应地拆分 Y 的训练集。Y和X一样分成5000个mini-batch集合。
然后执行向前传播和梯度下降


之前我们学习的神将网络梯度下降叫batch下降法
batch下降法和mini-batch下降法有什么不一样吗?
batch下降法每次都需要对整个数据集进行遍历,每次迭代都 需要对整个数据集进行前向传播和反向传播,计算出全局梯度。通常用于小型计算集
Mini-Batch 下降法 可以将数据分成小批量,并且每次计算梯度,只是针对每次的小批量来进行计算,更高效。如图

绿色线条为minibatch下降 紫色为随机梯度下降 蓝色为batch梯度下降
绿色更少更快
指数加权平均
什么是指数加权呢? 吴恩达视频中用了一个测量美国温度的例子来举例说明这个问题。让温度函数设置为$v_t = 0.9v_(t-1) + 0.1 \theta_(t)$ 类似如下

然后通过β的值来挑取天数
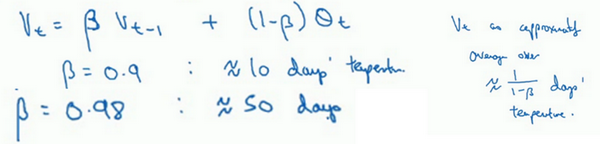

就这样通过不同的数值来选取不同的天数从得到温度曲线
β=0.5 得到平均了2天的温度 运行得到黄线

如何理解加权平均数
关键方程 $v_t = 0.9v_(t-1) + 0.1 \theta_(t)$

所以这是一个加和并平均,100号数据,也就是当日温度。我们分析 $v_{100}$
的组成,也就是在一年第100天计算的数据,但是这个是总和,包括100号数据,99号数据,97号数据等等。画图的一个办法是,假设我们有一些日期的温度,所以这是数据,这是 t ,所以100号数据有个数值,99号数据有个数值,98号数据等等, t 为100,99,98等等,这就是数日的温度数值。

然后构建指数衰减函数从0.1开始到 0.1 ∗ 0.9 0.10.90.1∗0.9 ,到 0.1 ∗ 0. 9 ,0.1 * $0.9^2$ ,以此类推,所以就有了这个指数衰减函数。

计算 $ v_{100}$ 是通过,把两个函数对应的元素,然后求和,用这个数值100号数据值乘以0.1,99号数据值乘以0.1乘以 $0.9^2$
,这是第二项,以此类推,所以选取的是每日温度,将其与指数衰减函数相乘,然后求和,就得到了 $ v_{100}$



总结:就是通过β的值不同可以预测不同曲线的温度
偏差修正

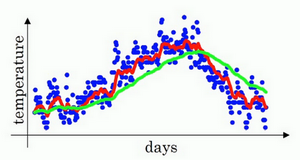
红色曲线对应β值为0.9 绿色曲线对应β值为0.98 。
但实际在β=0、98的时候得到的并不是绿色曲线,而是紫色曲线,你可以注意到紫色曲线的起点较低,我们来看看怎么处理。

总结:实用加权平均数偏差修正可以更好的减小误差。达到更精准的数据
动量梯度下降法
还有一种算法叫做Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法,简而言之,基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重,在本视频中,我们呢要一起拆解单句描述,看看你到底如何计算。


总结:意思就是在梯度下降的过程中,上下摆动的幅度变得很小,更新参数变得很慢很慢 ,从而需要给一点动量加速梯度下降的过程。反正是
减少纵轴方向的学习速度 加快横轴学习速度基于这个理念引入
RMSprop



在横轴也就是w方向 我们希望学习速度快,而在垂直方向,也就是b方向,我们喜欢减缓摆动,所以会希望$S_{dw}$相对较小,除以一个较小的数,从而使得W更新后变得不是很小达到加速效果 并且此时希望b方向变得较较小,那么就希望$S_{db}$尽量大,使得b更新减去后面的数的时候, 让b更变得尽量小。从而达到目的
Adam优化算法
Adam优化算法基本上就是将Momentum和RMSprop结合在一起,(Monmentum是动量梯度下降的意思 )
)



其中
是个缺省值 可要可不要
学习率衰减
有指数衰减和mini-batch梯度下降法
假设你要使用mini-batch梯度下降法,mini-batch数量不大,大概64或者128个样本,在迭代过程中会有噪音(蓝色线),下降朝向这里的最小值,但是不会精确地收敛,所以你的算法最后在附近摆动,并不会真正收敛,因为你用的 α \alphaα 是固定值,不同的mini-batch中有噪音。
但要慢慢减少学习率 α \alphaα 的话,在初期的时候, α \alphaα 学习率还较大,你的学习还是相对较快,但随着 α \alphaα 变小,你的步伐也会变慢变小,所以最后你的曲线(绿色线)会在最小值附近的一小块区域里摆动,而不是在训练过程中,大幅度在最小值附近摆动。
所以慢慢减少 α \alphaα 的本质在于,在学习初期,你能承受较大的步伐,但当开始收敛的时候,小一些的学习率能让你步伐小一些。
你可以这样做到学习率衰减,记得一代要遍历一次数据,如果你有以下这样的训练集,


总结:学习率衰减是加快算法的方法
什么是超参数? 很简单如cnn中的学习率α或者是Momentum(动量梯度下降法)的参数 β
超参数的调试
调试好超参数的范围
3.2 为超参数选择合适的范围-深度学习第二课《改善深层神经网络》-Stanford吴恩达教授_超学习为超参数选择合适的范围,比如选择神经网络的层数或者确定指数加权平均值中-CSDN博客
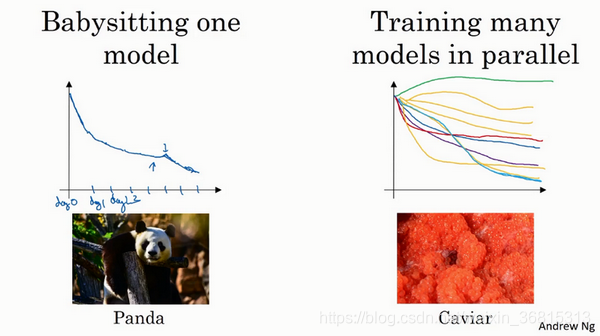
超参数的实践 PandasVS caviar
熊猫方法 vs甩籽方法
左边是一次只训练一个模型,所以很慢
右边是同时训练多个模型,对比梯度曲线获得更好的参数 如下图
正则化网络的激活函数
1先归一化 2在激活函数
归一化是加快训练速度
就是得到想要的Z的过程
普通神经网络得到的Z经过γ还有β的参数加入转换成$\hat{Z}$ 如下图

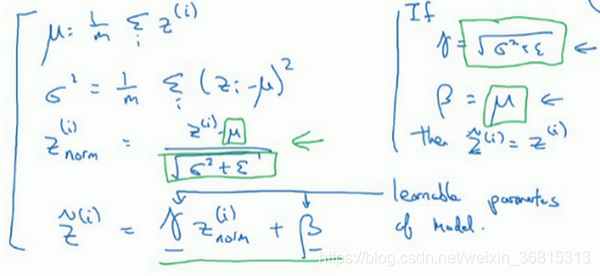
$\hat{Z^{[i]}}$代表的是某一层的第几个隐藏单元,若有表示第几次的隐藏单元可以这样写
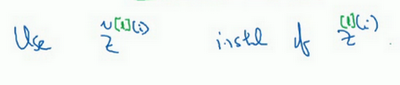
$\hat{Z}$其实就是下一层的输入 如下

batch norm 拟合神经网络
Batch归一化的关键步骤之一是在每个批次中计算特征的平均值,然后将这个平均值减去每个样本的对应特征值,以实现特征的归一化。这有助于确保每个批次中的特征在相似的尺度上,从而提高了深度神经网络的训练稳定性和速度。
由于计算$\hat{Z}$由于需要 先计算特征的平均值,然后将这个平均值减去每个样本的对应特征值。也就是需要+b然后-b 计算之间的差值
从而达到标准化的目的。所以我们可以不需要b的值(b值就是$b^{[i]}$)
batch norm函数会使我们的优化函数变得更容易优化
Batch归一化将你的数据以mini-batch的形式逐一处理,但在测试时,你可能需要对每个样本逐一处理,我们来看一下怎样调整你的网络来做到这一点。

在训练时,这些就是用来执行Batch归一化的等式。在一个mini-batch中,你将mini-batch的 $z^{(i)}$ 值求和,计算均值,所以这里你只把一个mini-batch中的样本都加起来,我用 m mm 来表示这个mini-batch中的样本数量,而不是整个训练集。然后计算方差,再算 $ z^{(i)}_{norm}$ ,即用均值和标准差来调整,加上 $ \epsilon$ 是为了数值稳定性。 $ \tilde{z} $ 是用 $\gamma$和 $ \beta$再次调整 $ z_{norm}$ 得到的。



SOFTMAX回归
二分分类叫logic回归 那么多种分类叫做 softmax回归,意思就是分类的选项更多。就是分更多类
具体计算如下
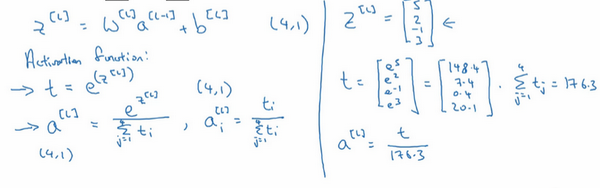
通常就是神经网络计算到z后在用softmax激活函数得到$\hat z$ 然后在得到概率
但是假如分两类就会回到logic回归上了
训练一个Softmax分类器
代码实践
3.9 训练一个 Softmax 分类器-深度学习第二课《改善深层神经网络》-Stanford吴恩达教授_trainable soft-max classifier-CSDN博客
深度学习框架tensorflow
1 | import math |
 微信
微信- 支付宝



